Paper Review: Neural machine translation by jointly learning to align and translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. (2015). Neural machine translation by jointly learning to align and translate. In Proceedings of ICLR.
Intro
Attention 구조는 10년 전, 언어 모델의 또 하나의 붐을 몰고 오는데 아주 큰 역할을 했다. 이 attention 모델의 시초를 “Attention is all you need”(Ashish et al., 2017)로 알고 있는 경우가 많은데, 이 논문이 의미 있는 이유가 attention을 처음 제안했기 때문은 아니었다. Transformer라는 새로운 모델을 제시함으로써 기존의 계산복잡도가 심각했던 recurrence 신경망 구조를 탈피하여 새로운 패러다임을 제시했고, 이때 attention을 Query, Key, Value의 구조로 명확히 하였다는 데에 의의가 있다. 그럼 attention은 언제 처음 제시되었던 것일까? 오늘은 그 논문을 파해쳐본다.
2014년 즈음, 신경망을 활용하여 번역 모델을 만들려는 여러 시도가 있었다. 대부분의 모델이 문장을 sequence를 입력 받고 sequence로 내뱉는 seq2seq 모델이었는데, 그 형태가 바로 encoder-decoder 이다. Encoder 구조는 입력 받은 문장을 고정된 크기의 벡터로 압축(->context vector)하는 역할을 하고, decoder 구조는 압축된 벡터로부터 번역된 문장을 출력하는 역할을 수행하였다. 하지만 encoder-decoder 구조는 치명적인 단점이 있었는데, 바로 긴 문장에 대해서는 성능이 가파르게 저하된다는 점이었다. Context vector는 생각보다 중요한 역할을 수행하는데, 이 벡터가 decoder한테 전달하는 유일한 벡터이기 때문이다. 때문에 encoder의 마지막 단계에서 생성되는 context vector에는 맨 처음에 입력된 정보도 거리를 이겨내고 충분히 반영하고 있어야 한다. 하지만 입력되는 문장이 길어진다면 이 과정이 힘들 것이다. 또한, 문장이 길어짐에 따라 입력되는 방대한 정보를 고정된 크기의 context vector에 모두 담아내야 하는 것도 한 몫 한다. 즉, 여기서 정보의 병목현상을 일으키는 것이었다.
Dzmitry Bahdanau(2015)는 이를 보완하고자 해결방법을 제안했는데, 번역 전 언어와 번역 후 언어가 어느 단어끼리 가장 비슷한 의미를 내포하는지 함께 정렬할 수 있도록 하고, 이에 따라 번역하는 것을 목표로 했다(learns to align and translate jointly). 여기에서 우리는 Attention 메커니즘의 시초를 엿볼 수 있다. 학습과정에서 모델이 번역되는 단어를 출력할 때면, 해당 단어가 원문의 단어들 중에서 어느 것과 가장 비슷하게 정보를 가지고 있는지 그 정보의 분포를 계산을 하게 된다. 이는 기존의 고정된 context vector로만 decoder에 정보를 전달하는 것과는 차이를 보이게 되는데, 매 output을 출력할 때마다 input sequence로 제공되는 정보를 똑같이 활용하는 것이 아니라, 필요한 정보를 적합하게 골라내어 활용하는 것이기 때문이다. 즉, 매 output을 예측할 때마다 context vector는 그때그때 맞는 최적의 정보가 무엇인지 학습하고(->adaptive context vector) 그 정보들을 담아 decoder에 전달할 것이다.
Background
번역 모델을 구성한다는 것은 기본적으로 다음 틀을 따른다.
- $x$: 원문(source sentence)
- $y$: 번역문(target sentence)
- optimization: $y = \text{argmax}_{y}\, p(y \vert x)$
우리는 적절한 모델 $p$를 찾는 것이다. 2014년 당시 SOTA 모델은 recurrence 신경망 계열이었는데, 이를테면 기본적인 RNN부터, 여기에 gradient descent 문제를 해결하기 위해 memory 장치를 추가한 LSTM 등이 있다. 이 단위들을 여러 개 이어붙이므로써 encoder-decoder 형태의 모델을 구현하였고, 이들에 대한 성능은 충분히 입증된 상황이었다.
대표적인 예시로 RNN encoder-decoder의 구조를 간략하게나마 살펴보자(Cho et al., 2014).
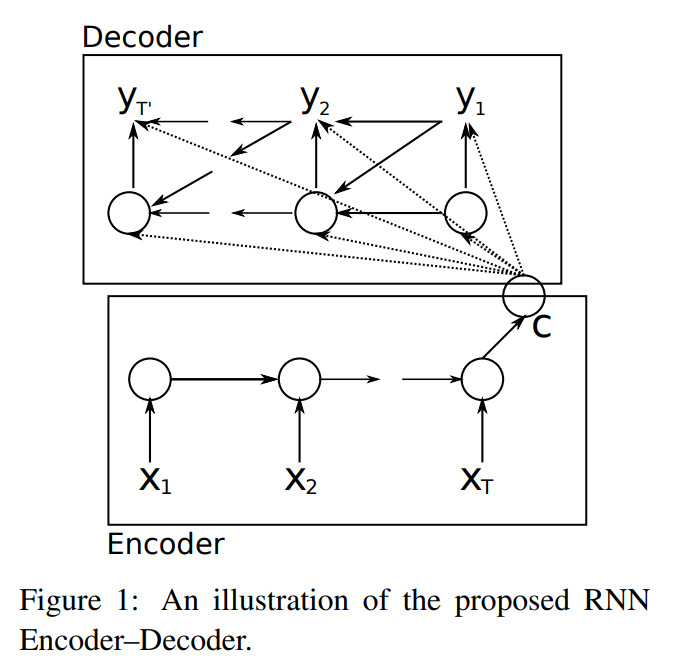
Encoder는 입력된 vector $x$를 encode하여 context vector $c$로 만드는 역할을 한다. 이때 RNN 구조를 직렬로 이어붙여서 hidden state(은닉층)을 만들었다.
- $x = (x_1, \cdots, x_{T_x})$: an input seq.,
- $h_t = f(x_t, h_{t-1})$: a hidden state at time $t$ where $f$ is an RNN, and
- $c = q({h_1, \cdots, h_{T_x}})$: a context vector.
Decoder에서는 이전에 예측한 결과와 context vector를 모두 활용하여 그 다음 단어를 예측하여 가능한 단어들에 대한 probability distribution을 만든다.
- $y = (y_1, \cdots, y_{T_y})$: an output seq.,
- ${y_1, \cdots, y_{t-1}}$: previously predicted words at time $t$, and
- $p(y) = \prod_{t = 1}^{T_y} p(y_t\vert y_{t-1}, \cdots, y_1, c)$: the prediction probability distribution where $p(y_t\vert y_{t-1}, \cdots, y_1, c) = g(y_{t-1}, s_t, c)$: $g$ is the decoder that only uses the last prediction, altogether with the hidden state $h_t$ produced by RNN and $c$ the context vector.
물론 RNN 구조가 활용된 $f$는 다른 적합한 모델로 대체될 수 있으며, LSTM, DeConvNN(Conv와는 반대로 depooling을 계속 거침) 등 많은 연구에서 여러 가지로 시도하였다.
Learning to Align and Translate
전체적인 부분을 보았을 때 기존 RNN encoder-decoder와 구조적으로 다른 점은 다음과 같다.
- Encoder: consists of a bidirectional RNN, and
- Decoder: mimic searching process through attention algorithm.
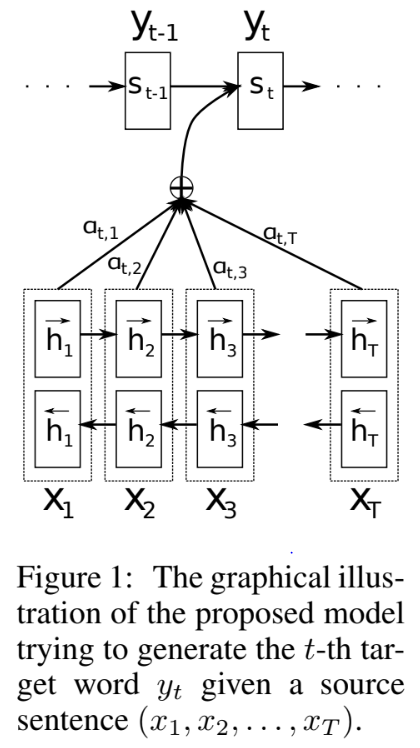
..Decoder
Decoder부터 그 구조를 살펴보자. Decoder는 똑같이 $p(y) = \prod_{t = 1}^{T_y} p(y_t\vert y_{t-1}, \cdots, y_1, c)$를 제시할 텐데, 이때 다른 점은
\[p(y_i\vert y_{i-1}, \cdots, y_1, x) = g(y_{i-1}, s_i, c_i)\]where
\[c_i = \sum_{j=1}^{T_x} \alpha_{ij}h_j\]라는 것이다. 즉, context vector $c_i$가 모든 예측에서 동일하게 주어지는 것이 아님을 확인할 수 있다. 이때 $(h_1, \cdots, h_{T_x})$는 input sequence의 각 단어 요소가 encoder를 거치면서 오는 embedding vector(-> 저자는 annotation이라고 불렀다)라고 생각하면 되는데, encoder를 설명할 때 자세하게 설명한다.
Attention의 아이디어는 바로 $\alpha_{ij}$에 담겨있다. 이 계수는
\[\alpha_{ij} = \text{Softmax}_i (e_{ij}) = \frac{\exp(e_{ij})}{\sum_{k=1}^{T_x}\exp(e_{ik})}\]로 계산이 되는데, 이때 $e_{ij} = a(s_{i-1}, h_j)$는 alignment model이라고 불리는 것으로 $i$번째 output이 $j$번째 input 주변과 얼마나 잘 들어맞는지를 평가한다. 그러므로 input에서 비롯되는 $j$번째 annotation $h_j$와, decoder에서의 $(i-1)$번째 hidden state $s_{i-1}$를 비교하여 평가하게 된다. 각각의 점수 $e_{ij}$가 계산되었다면, $\alpha_{ij}$는 각각의 score들에 softmax 함수를 취하여 계산되므로, 이는 일종의 가중치, 혹은 확률로 볼 수 있다. 따라서 $c_i$는 annotation들이 현재 output과의 관련도(alignment)를 반영한 가중합, 혹은 기댓값이라고 볼 수 있다. 즉, alignment에 따라 어느 annotation에 집중(attention)할지를 결정할 수 있고, 그러므로 encoder에서 압축한 정보인 annotation 중에서 필요한 정보만 되찾아(retrieving) output 출력 시 반영하게 된다.
참고로 $a$를 alignment model이라고 따로 불렀는데, fully connected NN을 썼다고 한다. 그런데 이것도 나름 의미가 있는 것이, 이렇게 추가 장치를 활용하였음에도 이 장치가 따로 노는 것이 아닌, 전체 모델 학습 시 함께 backpropagation이 가능하도록 설계하였다는 점이다. 즉, 모델 학습을 할 때 모델 $a$도 함께 학습이 되며 이에 따라 적절한 $\alpha_{ij}$가 계산되도록 한 것이다.
..Encoder
통상적으로 encoding을 할 때에는 RNN을 문장 순서에 맞게 순차적으로만 연결하여, 어떤 단어에 대한 이전 단어들의 정보만을 반영하였다. 하지만 여기에서는 bidirectional RNN을 시도함으로써 비단 이전 단어뿐만이 아니라 해당 단어가 문장 이전과 이후 단어들과 어떤 관련이 있는지를 모두 파악할 수 있도록 했다.
사견이지만 BiRNN을 활용한 짐작되는 이유가 있다. BiRNN라는 개념이 이 논문에 의해 처음 제시된 것은 아니었다. 하지만, decoder에서 attention이 구현된 이상 각 input에 대한 중요도에 따라 정보를 차등 반영할 수 있게 되었으므로 encoder에서는 문장 순서 관계까지 애써 반영하기보다는 해당 단어가 문장 전체에서 어떤 역할을 수행하는지를 최대한 반영하는 것이 훨씬 더 중요했을 것이다. 그리고 때론 단어의 역할이 그 뒤에 등장하는 단어에 의해서 특정 지어지기도 한다.
Forward RNN $\overrightarrow{f}$는 순서대로 input sequence를 읽어나가면서 hidden state $\overrightarrow{h_i}=\overrightarrow{f}(\overrightarrow{h}_{i-1}, x_i)$를 생성한다. 비슷하게 backward RNN $\overleftarrow{f}$는 input sequence를 역순으로 읽어나가면서 hidden state $\overleftarrow{h_i} = \overleftarrow{f}(\overleftarrow{h}_{i+1}, x_i)$를 생성한다. 최종 annotation vector는 이 둘을 단순히 concate해서 도출한다. 즉, $h_i = \left[\frac{\overrightarrow{h}_i}{\overleftarrow{h}_i}\right]$.
Experiments and Results
..Performance
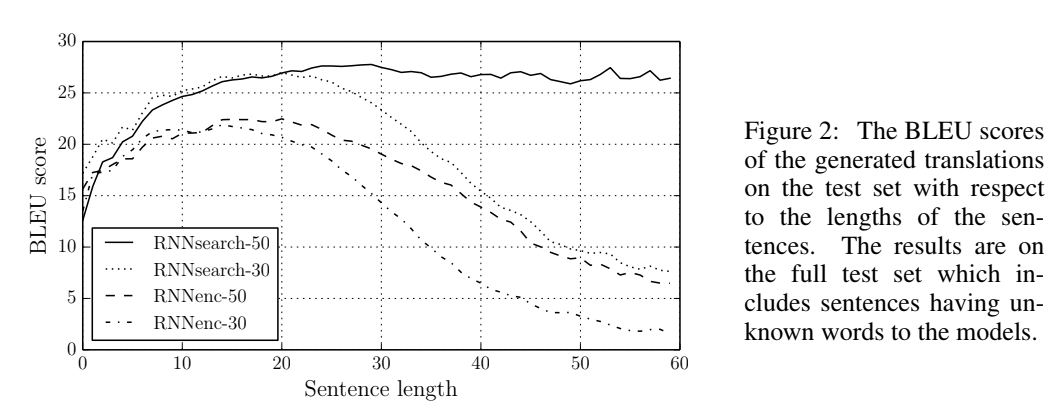
RNNsearch가 이 논문에서 제시한 모델이고, 그 뒤 넘버링은 학습할 때 입력한 최대 문장 길이이다. RNNenc 모델은 기존 RNN Encoder-Decoder에서 별다른 장치를 추가하지 않은, background에서 소개한 그 모델이다. 두 모델 모두 1000개의 hidden state($T_x=T_y=1000$)을 적용했으며, SGD로 80문장씩 minibatch로 학습했고 학습하는 데 대략 5일 정도 걸렸다고 한다(..너무 tmi인가?). BLEU score를 비교한 위 그래프를 보면 문장 길이가 길어질 수록 급격한 성능 저하를 겪는 것이 기존 문제점(심지어 긴 문장을 학습 데이터에 넣어도!)인데, 이 문제가 잘 해결된 모습을 볼 수 있다.
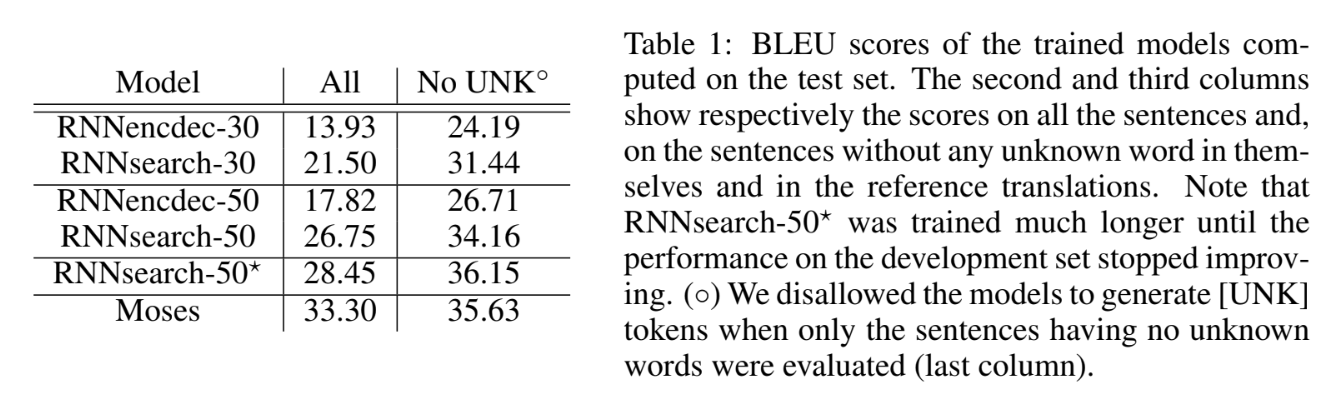
아래 표에서는 이 논문에서 제시한 모델의 구체적인 BLEU score를 확인할 수 있다. Test set을 기준으로 산정된 점수이며, “No UNK” column은 <UNK>토큰이 아예 없는 문장을 학습시켰을 때 도출된 모델 성능(output에서도 <UNK>토큰을 출력하지 못하도록 했다고 한다)이다.
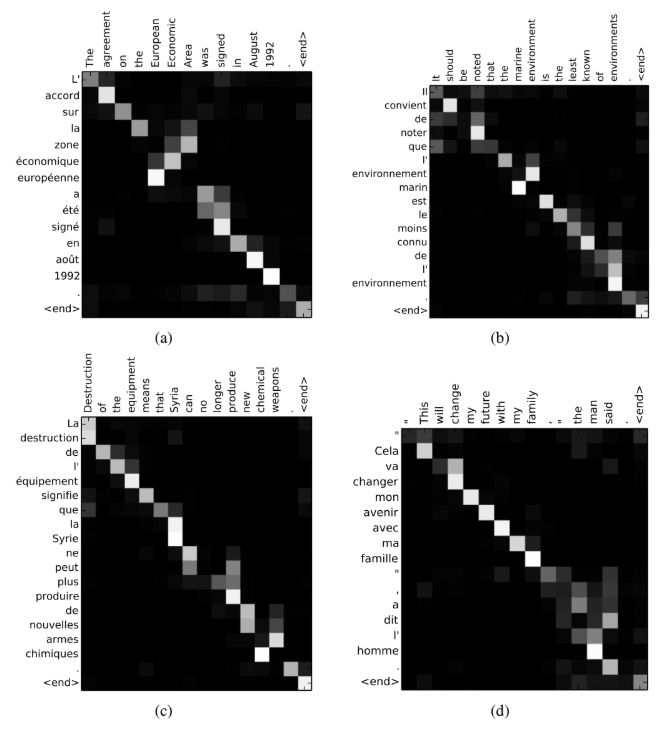
아래 그림은 영어로 주어진 문장을 프랑스어 문장으로 번역할 때 alignment model에서 계산된 $\alpha_{ij}$의 값들이다. 무엇보다도 alignment를 계산하기 위해 넣은 attention 장치가 의도대로 작동한 모습을 볼 수 있다.
..Drawbacks
저자는 attention 기법을 제시함으로써 기존의 문제점은 해결했지만, 아직은 단점이 존재한다고 설명했는데 바로 시간복잡도이다. 15~40 단어 정도의 문장은 괜찮지만, 만약 문장이 이보다 길어지면 annotation 계수를 계산하는 과정이 극도록 복잡해질거라는 것이다.
또한, 빈도가 낮거나 학습 과정에서 등장하지 않은 unknown word를 더욱 유연하게 다룰 수도 있어야 한다. 이 문제를 해결한다면 여기에서 제시한 논문보다 SOTA일 것이라고 저자는 장담했다.
Bibilography
Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention model. (2016). In Empirical Methods in Natural Language Processing, 2016.
Cho, K., van Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., and Bengio, Y. (2014a). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014).
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin. (2017). Attention Is All You Need. In Advances in Neu-ral Information Processing Systems 30: Annual Conference on Neu-ral Information Processing Systems 2017.