Sufficiency(충분성)
이제부터 기초적인 inference 과정을 밟기 위한 준비를 할 것이다. 특히 이번 post에서 도입되는 개념인 sufficiency는 data의 정보를 잃지 않고 하나의 수치로 요약할 수 있는 statistics통계량이 가지는 특성인데, 이는 inference를 하는 과정에서 끊임없이 활용한다.
Estimators추정량 and Risk Functions위험함수
기본적으로 통계학에서 inference를 한다는 것은 data $X$가 비롯된 distribution의 알려지지 않은 parameter $\theta$를 알아가는 단계부터 시작한다. 비단 unknown parameter의 prediction만이 inference에 해당하는 것이 아니고, predict한 parameter가 어떤 특성을 포함하고 있고 그것을 다양한 시각에서 해석하는 영역이다. Parameter $\theta$는 단지 constant만 나타내는 것은 아니고 vector 형태일 수 있음에 유의하라. 우리는 $\theta$에 대한 inference를 위해 $X$로부터 정보를 얻을 것이다.
$X$의 distribution은 결국은 $\theta$에 의해 결정되고, 그 $\theta$에 따라 우리는 $X\sim P_{\theta}$라고 표기한다. Model은 여러 후보들 $\mathcal{P} = \{P_{\theta}: \theta\in\Omega\}$를 제시해주고 우리는 data $X$의 정보를 통해 적절한 $\theta$를 estiamte하여 $P_{\theta}$를 결정하는 일련의 과정이 가장 큰 틀이다. 즉, model은 하나의 $\theta\mapsto P_{\theta}$의 형태를 갖는 mapping이며, 때로는 $\mathcal{P}$이라고도 말할 때도 있다. 이때 $\Omega$는 parameter 값들로 가능한 것의 집합, 혹은 parameter 값들의 후보들이며 parameter space모수공간이라고 부른다.
Statistic통계량은 $X$에 관한 함수이며, data가 여러 개의 값을 통해서 제공하는 정보의 일부를 하나의 값으로 제공해준다는 특징이 있다. 가장 대표적인 것이 sample mean인데, 우리가 data로부터 평균을 구하는 것도 data가 대강 어느 정도의 위치에 있는지 파악하기 위해서 data의 많은 값들을 이용하여 하나의 값으로 요약한다.
\[\delta(X) = \overline{X} = \frac{X_1+\cdots +X_n}{n}\]이 자리에서는 inference 중에서도 $\theta$를 estimate하는 방법론에 대해서 살펴볼 것이다. 적절한 statistics $\delta = \delta(X)$를 찾아서 알려지지 않은 parameter의 함수 $g(\theta)$를 잘 예측하는 것을 목표로 삼는다. 이때 이러한 $\delta$ 혹은 $\delta(X)$를 $g(\theta)$의 estimator추정량이라고 부른다. $g$는 아무거나 될 수 있는데, 기본적으로 $g(\theta) = \theta$도 물론 가능하고, 특히 $\theta$가 vector일 때, paraneter의 특정 element에 대해서만 관심 있을 때 $g(\theta) = \theta_k$로 두어도 된다.
Example 6.1 동전을 던저 앞면이 나올 probability를 추정하는 실험을 한다고 하자. 우리는 동전을 100번 던져서 앞면이 나온 횟수 $X$를 data로 얻었다. 먼저 model를 구성해보자. Model은 $X$가 기본적으로 어떤 형태의 distribution을 따르는지 결정하여 $X$와 $\theta$의 관계를 결정해준다. 우리는 이러한 형태에서 $X$가 binomial distribution을 따르는 것이 가장 합당하다고 생각했다. Independent한 trial이고, 각각의 trial은 모두 동일한 형태와 동일한 probability를 가지므로 binomial가 성립되는 과정과 매우 똑같다. 그러므로
\[X\sim B(100, \theta)\]이고 $P_{\theta} = B(100, \theta), \quad \theta\in[0, 1] = \Omega$라고 하면, 우리는 model를 다음과 같이 100번의 시행의 binomial distribution들의 집합으로 잡아둔 것이다.
\[\mathcal{P} = \{P_{\theta}:\theta\in\Omega\}\]
이제 estimator로 가장 적절한 것을 찾아보려고 한다. 위의 예시 Example 6.1에 대하여 가장 직관적인 estimator는 $\delta(X) = X/100$이다. 좋은 estimator인지는 아직 모르지만, 100번 중에 앞면이 나온 빈도 수가 곧 probability일 것이라는 직관에 의해 제시된 것이다. 하지만, 이 estimator가 얼마나 좋은 performance를 가지고 있는 지 정량화할 필요가 있다. 이는 곧 어느 estimator를 고를 지에 대한 이론인 decision theory로 귀결되는데, 그 시작이 바로 loss function손실함수를 정의하여 비교해보는 것이다. $L(\theta, d)$는 parameter $\theta$에 대하여 $d$는 $g(\theta)$의 estimator로 주어졌을 때 어느 정도의 loss를 가지는 지 보여준다. 그러므로 $L(\theta, g(\theta)) = 0$이라고 가정하는 것이 매우 합당한데, $g(\theta)$의 estimator로 true value참 값 $g(\theta)$를 사용했기 때문이다. 나머지 estimator $d$에 대해서는 어느 정도의 loss가 발생될 것이므로 loss function은 non-negative의 값을 가진다.
그리고 이 loss가 0을 가지지 못한다고 하여 그렇게 불행한 일은 아니다. 그 이유는 estimator $d$로 보통 data로부터 도출된 statistic인 $\delta(X)$를 활용하게 될 터인데, data $X$ 그 자체로도 random 요소가 있으므로 $\delta(X)$은 물론, $L(\theta, \delta(X))$도 random 한 요소를 가지게 된다. 따라서 이 모든 random한 요소를 종합적으로 판단하기 위해서는 expectation을 씌워주는 것이 좋은 방법이다. 이렇게 하여 정의된 것이 바로 risk function이다. 즉, risk function $R$은 다음과 같이 정의된다.
\[R(\theta, \delta) = E_{\theta} L(\theta, \delta(X))\]이때 $E_{\theta}$는 $X\sim P_{\theta}$일 때의 expectation임을 의미한다. $\theta$에 따라 distribution도 바뀌므로 expectation을 구할 때 어느 $\theta$에 대한 expectation인지 명시할 필요가 있다. Loss와 risk모두 어떤 고정된 true value $\theta$에 대해서 다루고 있었으므로 이에 해당하는 expectation을 씌워준 것이다.
Example 6.2 위의 예시 Example 6.1을 이어서 살펴보자. 우리가 예측하고 싶은 것은 $g(\theta) = \theta$이고 제시된 estimator는 $\delta(X) = X/100$였다. 여기서는 loss function을 다음과 같이 두자.
\[L(\theta, d) = (\theta - d)^2\]이 loss function은 squared error loss라고 불리는데, 말 그대로 true value와 estimate한 값의 차이를 제곱한 것을 loss로 표현했기 때문이다. 이 loss function은 quadratic이차식의의 형태이기 때문에 true value와 estimate된 값의 차이가 벌어질 수록 제곱했을 때 더 크게 값이 부풀려진다. 그러므로 차이가 크면 클 수록 더 많은 penalty벌칙(?)를 부여한다는 특징이 있다.
$\delta$의 risk는 그러므로 다음과 같이 구해진다.
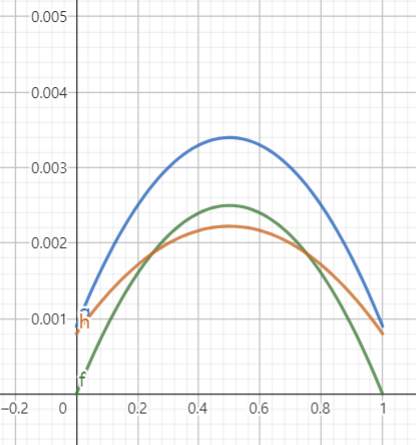
\[R(\theta, \delta) = E_{\theta}\left(\theta - \frac{X}{100}\right)^2 = \frac{\theta(1-\theta)}{100}, \quad \theta\in[0, 1]\]이 risk function의 그래프 형태는 0과 1을 지나고 1/2일 때 최댓값을 갖는 이차함수의 형태이다. 하지만, risk function만으로는 더 좋은 estimator을 선택하는 것이 힘든 일일 수 있다. 이를 테면 다음 세 가지 estimator들을 비교해보자.
\[\begin{align*} \delta_0(X) &= X/100 \\ \delta_1(X) &= (X+3)/100 \\ \delta_2(X) &= (X+3)/106 \end{align*}\]이들의 risk function을 구하면 다음과 같다.
\[\begin{align*} R(\theta, \delta_0) &= \theta(1-\theta)/100 \\ R(\theta, \delta_1) &= 9/100^2 + \theta(1-\theta)/100 \\ R(\theta, \delta_2) &= (9-8\theta)(1+8\theta)/106^2 \end{align*}\]$R_1$은 초록색, $R_2$는 파란색, $R_3$는 빨간색으로 아래와 같이 나타난다.
각각의 $\theta$의 범위마다 risk 값이 가장 작게 나타나는 estimator가 달라지는데, 막상 $\theta$의 true value는 알 수가 없으므로 어느 상황에서 어느 estimator를 활용해야 할지 명확하지 않다. 이 문제는 궁극적으로 risk function만 가지고 estimator를 선택할 수 없음을 시사한다. 또, 과연 loss를 expectation을 취하면 estimator의 performance를 파악할 수 있다는 아이디어 자체에 무언가 놓치는 부분이 있기도 하다. 지금 당장은 감이 오지 않겠지만, 이에 대해서는 이후에 차근차근 다룰 것이다.
Sufficient Statistics충분통계량
우리는 특별한 statistic 하나를 알아볼 것이다. 이 statistic은 그 하나의 값만으로도 data 전체의 정보를 움켜쥐고 있어 data를 요약할 때, 혹은 대표할 때 아주 유용하다. 또, 이 statistic을 가지고 여러가지로 응용이 가능하다.
예시 하나로 시작해보자. 서로 independent한 random variables $X$와 $Y$가 똑같은 Lebesgue measure하의 똑같은 density $f_{\theta}$를 가진다고 하자.
\[f_{\theta}(x) = \begin{cases} \theta e^{-\theta x}, & x\ge 0 \\ 0, & x\lt 0 \end{cases}\]그리고 $U$는 $X$와 $Y$와 independent한 $(0, 1)$위의 uniform distribution을 따르는 random variable이라고 하자. $T = X+Y$라고 하고 다음을 정의하자.
\[\tilde{X} = UT, \quad\quad \tilde{Y} = (1-U)T\]새로 정의한 $\tilde{X}$와 $\tilde{Y}$들의 joint density를 구해보려고 한다. 먼저 $T$의 분포가 필요할 것 같다. $T$의 density를 구할 땐 $(X, Y) \mapsto (X, T)$로 transformation 시켜서 구해도 되겠지만, 여기서는 smoothing(혹은 iterated expectation rule; $EX = EE[X\vert Y]$)을 이용해보자. $X$와 $Y$가 independent하다는 것을 활용하면,
\[\begin{align*} P(T\le t \vert Y = y) &= P(X+Y \le t\vert Y = y)\\ & = P(X\le t - y\vert Y = y) = P(X\le t -y) = F_X(t - y) \end{align*}\]따라서 smoothing에 의해 $T$의 CDF는
\[F_T(t) = P(T\le t) = EP(T\le t\vert Y) = EF_X(t - Y)\]$Y<t$에서 $F_X(t - y) = 1 - e^{-\theta(t - Y)}$이고 나머지는 0이므로
\[F_T(t) = \int_0^t (1 - e^{-\theta(t-y)})\cdot \theta e^{-\theta y}\, dy = 1 - e^{-\theta t} - t\theta e^{-\theta t}\]이고 미분하여 $T$의 density를 구하면
\[p_T(t) = \begin{cases} t\theta^2 e^{-\theta t}, & t\ge 0 \\ 0, & t <0 \end{cases}\]$T$와 $U$ 역시 independent하기 때문에 $(T, U)$ joint density는
\[p_{\theta}(t, u) = \begin{cases} t\theta^2 e^{-\theta t}, & t\ge 0, u \in (0, 1) \\ 0, & \text{otherwise} \end{cases}\]으로 구해진다. 마지막으로 transformation $(T, U)\mapsto (\tilde{X}, \tilde{Y})$를 통해 $(\tilde{X}, \tilde{Y})$의 density를 구하면
\[\begin{align*} p_{\theta}(x, y) &= p_{\theta}(u, t) \bigg\vert \frac{\partial (u, t)}{\partial (x, y)}\bigg\vert \\ &= \begin{cases} t\theta^2 e^{-\theta t}\cdot \frac{1}{x+y}, & x\ge 0, y\ge 0 \\ 0, & \text{otherwise} \end{cases} \\ &= \begin{cases} \theta^2 e^{-\theta (x+y)}, & x\ge 0, y\ge 0 \\ 0, & \text{otherwise} \end{cases} \end{align*}\]놀라운 점을 혹시 발견하지 않았는가? $(X, Y)$의 joint density를 한 번 구해보면
\[p_{\theta}(x, y) = p_X(x)\cdot p_Y(y) = \begin{cases} \theta^2 e^{-\theta (x+y)}, & x\ge 0, y\ge 0 \\ 0, & \text{otherwise} \end{cases}\]이 도출된다. 즉, $(X, Y)$의 joint density와 $(\tilde{X}, \tilde{Y})$의 joint density가 동일하다는 것이다. 이 점 자체로는 그렇게 흥미로운 점이 없을 지 몰라도, 우리가 주목해야 하는 것은 $(\tilde{X}, \tilde{Y})$는 $T = X+Y$와 $U$로 구성되어 있었는데 $U$는 data $X$하고 $Y$와 아무런 관계가 없었다는 것이다. 즉, $T$ 혼자서 $\theta$의 정보를 온전히 전달하는 데 역할을 다했다. 그리고 우리는 그러한 $T$와 생뚱맞은 $\mathcal{U}(0, 1)$에서의 random number $U$를 이용하여 fake data $(\tilde{X}, \tilde{Y})$를 만들었는데, density의 관점에서 real data $(X, Y)$와 한 끗 차이도 찾지 못했다. 즉, $(\tilde{X}, \tilde{Y})$가 어떤 값으로 주어졌다면, 사실 $(\tilde{X}, \tilde{Y})$가 그 값으로 나오게 할 real data $(X, Y)$는 정말 많을 테지만 real data가 그중 무엇이었든 상관 없이 $\theta$에 관한 inference는 모두 동일하다. 이와 같은 성격을 지닌 $T$를 sufficient statistic충분통계량이라고 부른다. Fake data $(\tilde{X}, \tilde{Y})$를 구성하면서 알 수 있었듯, $T$만 주어진다면 나머지 정보는 $\theta$의 추가 정보를 전달하진 않음을 알 수 있다. 그러므로 $(X, Y)$ joint density에 $T$에 대해서 condition을 걸어주면 $\theta$와는 무관한 probability가 도출되고, 그것을 식으로 정확하게 풀어낸 것이 $(\tilde{X}, \tilde{Y})$에서의 $U$의 역할이다. 즉,
\[P_{\theta}\left[\begin{pmatrix}X\\ Y\end{pmatrix}\in B \bigg\vert T = t\right] = P\left[\begin{pmatrix}Ut \\(1-U)t\end{pmatrix}\in B\right]\]우변의 probability는 $\theta$와 관련없음을 확인하라. 이러한 점을 이용하여 우리는 sufficient statistics를 일반적으로 정의할 수 있다.
Definition 6.3 Random variable $X$가 family $\mathcal{P} = \{P_{\theta}: \theta\in\Omega\}$에 속하는 한 distribution을 따른다고 하자. 이때 $T = T(X)$가 $\mathcal{P}$의(혹은 $X$의, 혹은 $\theta$의) sufficient statistic라는 것은, 모든 $t$와 $\theta$에 대하여 $X\vert T = t$가 $P_{\theta}$ 아래에서 $\theta$에 depend하지 않을 때를 말한다.
만약 $T$가 sufficient하다고 하고 다음을 정의하자.
\[Q_t(B) = P_{\theta}(X\in B\vert T = t)\]그러면 $P_{\theta}(X\in B\vert T) = Q_T(B)$라고 할 수 있다. 이는 sufficiency 정의에 의하여 좌변의 확률이 더이상 $\theta$에 관련되어 있지 않기에 그렇다. Smoothing에 의하여
\[P_{\theta} (X\in B) = E_{\theta} P_{\theta} (X\in B \vert T) = E_{\theta} Q_T(B)\]가 성립한다. 이를 잠시 제쳐두고, fake data를 구성해보도록 하자. 위에서 했던 것과 비슷한 맥락으로 $T = t$가 주어졌을 때 정말 아무 숫자나 배정할 것이다. 이를 조금 더 통계적으로 표현하면, fake data $\tilde{X}$에 대하여 $\tilde{X} \vert T = t$가 $\theta$와 무관한 distribution을 따른다고 하자. 즉,
\[\tilde{X}\vert T = t\sim Q_t\]그러면 smoothing에 의하여
\[P_{\theta} (\tilde{X}\in B) = E_{\theta}P_{\theta}(\tilde{X}\in B\vert T) = E_{\theta} Q_T(B)\]따라서 real data $X$와 fake data $\tilde{X}$의 distribution이 서로 동일함을 알 수 있다. 이는 결국 다음의 당연하면서도 꽤나 그럴싸한 결과를 가져온다.
Theorem 6.4 Random variable $X$가 family $\mathcal{P} = \{P_{\theta}: \theta\in\Omega\}$에 속하는 한 distribution을 따른다고 하자. $g(\theta)$의 임의의 estimator $\delta(X)$에 대하여, 동일한 risk function을 갖는 $T$를 base로 하는 randomized estimator가 항상 존재한다. 여기서 $T$를 base로 하는 randomized estimator란 $T$를 함수로 하고 보조로 아무 random number가 활용되어 만들어지는 estimator를 일컫는다.
Proof: 위에서 보았듯이 $\tilde{X}$는 $T$와 임의의 random number를 활용하여 충분히 만들어낼 수 있고, 주어진 $\delta(X)$에 대하여 $\delta(\tilde{X})$는 우리가 찾던 randomized estimator일 것이다. 그리고 이렇게 찾은 $\delta(\tilde{X})$가 원래 estimator $\delta(X)$와 risk function이 동일할 수밖에 없는 이유는 $X$와 $\tilde{X}$가 모두 동일한 distribution $P_{\theta}$를 가졌기 때문이다.
이 sufficiency는 비단 statistics에만 활용할 수 있는 것은 아니다. 1951년 Blackwell은 이 sufficiency라는 표현을 두 experiment에서의 model를 비교할 때도 활용하였다. 만약 $\mathcal{P} = \{P_{\theta}: \theta\in\Omega\}$와 $\tilde{\mathcal{P}} = \{\tilde{P}_{\theta}: \theta\in\Omega\}$이 두 experiment에서 쓰였던 model이라고 한다면, $\tilde{\mathcal{P}}$가 sufficient하다고 하는 것은 fake data가 $\tilde{\mathcal{P}}$와 외부의 임의의 random number로 생성될 수 있으면서 그 distribution이 $\theta$와 관계 없이 다른 experiment에서의 real data와 일치하다는 것이었다. 이를 조금 수학적으로 쓰면 다음과 같다.
Definition 6.5 Model $\tilde{\mathcal{P}}$이 model $\mathcal{P}$보다 sufficient하다는 것은, 모든 Borel set $B$와 모든 $\theta\in\Omega$에 대하여 다음을 만족하는 stochastic transition kernel $Q$가 있을 때를 말한다.
\[P_{\theta}(B) = \int Q_t(B)\,d\tilde{P}_{\theta}(t)\]
Stochastic transition kernel에 대해서는 conditional distribution을 정의할 때 다시금 다루게 될 테고 stochastic process에서 자주 등장하는 개념이지만, 여기서는 간단히 정의만 살펴보도록 하자. Stochastic transition kernel $Q$는 $Q: \mathcal{X}\times\mathcal{B}\to [0, 1]$의 함수로 정의되며, 다음의 성질을 만족한다.
- $x\in\mathcal{X}$에 대하여, $Q_x(\cdot)$은 $\mathcal{B}$ 위에서 probability measure이다.
- 모든 $B\in\mathcal{B}$에 대하여, $Q_x(B)$는 $x$에 대해 measurable function이어야 한다.
가장 직관적으로 생각하는 것은 $Q_x(B)$를 conditional density라고 생각하는 것인데(뒤에서 실제로 conditional density를 이를 이용하여 표현할 것이기도 하고…) discrete conditional density로 생각하면
\[Q_x(B) = P(Y\in B\vert X =x)\]즉, $x$를 condition된 값(아니면 현재의 상태)으로 잡은 후 그 condition 아래에서 관심있는 event를 $B$라고 생각하면 된다. 그러면 위의 정의가 조금이나마 합당해질 텐데, 1번 조건은 고정된 $x$에 대하여 $Q_x(\cdot)$ probability measure여만 $Y$의 probability를 표현할 수 있을 것이다. 2번 조건은 condition $x$에 대해서 적분이 필요한 경우가 많기 때문에 생긴 합당한 조건이라고 할 수 있다.
다시 돌아와서, 지금의 맥락에서 $Q_t(\cdot)$가 하는 역할은 fake data를 만들기 위해 주어진 $T = t$에 대하여 임의의 random number를 생성해주는 distribution이다. 그러므로 만약 $\tilde{\mathcal{P}}$가 $\mathcal{P}$에 대해 sufficient하고, 그 sufficient experiment으로부터 $T\sim \tilde{P_{\theta}}$를 추출했다고 하자. 그러면 fake data $\tilde{X}$는 주어진 $T = t$에 대해 $\theta$와 무관한 $Q_t$에서 random으로 sampling 해주어 만들면 된다. 즉,
\[P(\tilde{X}\in B\vert T = t) = Q_t(B)\]그렇게 하여 만든 fake data의 distribution $\int Q_t(\cdot)\,d\tilde{P_{\theta}}$이 real data의 distribution $P_{\theta}(\cdot)$와 같게 되는 것이다. 그것이 Definition 6.5에서 보여주고자 했던 것이다.
Sufficient statistics가 갖는 의미는 잘 파악했지만, 아직 문제가 하나 남아 있는 것은 과연 이러한 sufficient statistics를 어떻게 찾을 것이냐이다. 다음 post에서는 이를 쉽게 찾을 수 있도록 도와주는 factorization theorem분해 정리에 대해 다룰 것이다.